









Table of Contents
Most interesting problems scale extremely badly. You cannot just assume that more data and more compute means smarter AI. - Yann LeCun, Chief AI Scientist at Meta, keynote at the National University of Singapore.
Artificial intelligence (AI) keeps shrinking to fit a pocket while its language skills expand. Small language models (SLMs) prove this shift, offering lean, accurate, and secure alternatives to heavyweight Large language models (LLMs). SLMs are perfect for teams that need speed and privacy without a cloud bill shock. That is why the SLM market is booming.
Today, LLMs have taken root with up to 70% of organizations, by some estimates. LLM providers are racing to make AI models as efficient as possible. Instead of enabling new use cases, these efforts aim to rightsize or optimize models for existing use cases. For instance, massive models are not necessary for mundane tasks like summarizing an inspection report; a smaller model trained on similar documents would suffice and be more cost-efficient.
Don’t get us wrong. LLMs still rule multi‑purpose generative AI. However, in the race of optimization and efficiency, businesses now explore lighter alternatives to deliver accuracy, lower cost, and tighter security at the edge.
This guide explains SLM meaning, shows how these compact AI models work, portrays where they shine, and indicates when to pick an SLM vs. LLM solution for your next project. So, stay tuned!
What are Small Language Models (SLMs)?
Small language models (SLMs) are neural‑network‑based AI models trained to understand and generate text with far fewer parameters, often millions rather than the billion parameters inside today’s LLMs. An SLM AI concentrates its knowledge on a narrow domain, so the model fits onto edge devices or a lightweight cloud instance.
In short, what does SLM mean? A compact, task‑focused engine that brings generative AI wherever limited computational resources exist.
Think of an SLM as a pocket‑sized travel dictionary:
- light;
- focused;
- easy to carry;
- perfect for quick look‑ups.
An LLM is the entire national library, vast and versatile but impossible to slip into your back pocket.
Millions vs. billions of parameters
In practice, the SLM definition is about the model that might range from only a few million up to a few billion parameters, in contrast to LLMs with hundreds of billions or even trillions. Thanks to this smaller scale, SLMs are more compact and efficient.
They demand less memory and compute power, which enables deployment in resource-constrained environments like smartphones, IoT devices, or offline on-premises setups. In essence, SLMs trade breadth for efficiency, focusing on narrower vocabularies or specialized knowledge while still leveraging advanced AI architectures.
Generally, the architecture of small language models (SLMs) is based on LLMs but optimized for computational efficiency and scalability. SLMs commonly employ the Transformer architecture. It utilizes self-attention mechanisms to manage long-range text dependencies, essential for maintaining performance with constrained resources.
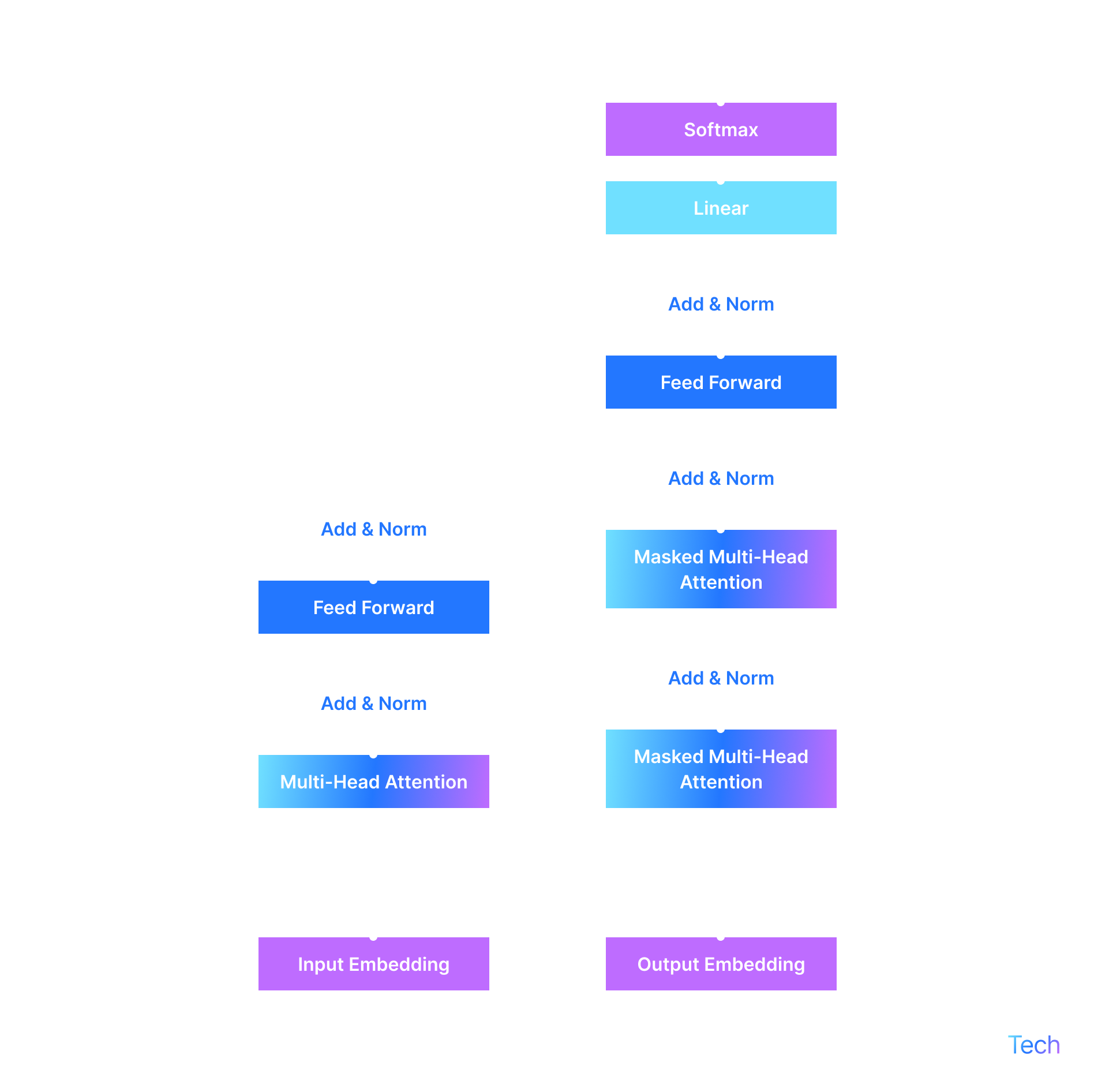
How do SLMs work?
Behind every compact SLM sits smart engineering. Instead of reinventing the wheel, developers squeeze insight from massive teachers, trim excess weight, and ship a nimble student you can run almost anywhere.
Picture a chef reducing a rich broth into a concentrated demi‑glace. Distillation, pruning, and quantization boil a large model down to its essential flavors while slashing volume, perfect for quick‑serve kitchens (edge devices) that lack industrial stoves (cloud GPUs).
1. Training data → Transformer architecture. These bars and molecule icons map to the bulk ingredients in our broth analogy. Engineers feed curated corpora into a transformer, then apply knowledge distillation, pruning, and quantization to concentrate insight, just as a chef reduces stock into demi‑glace.
2. Training Small Language Model. The center micro‑chip represents the lean neural network born from compression. It embodies the “nimble student” that now carries essential patterns while shedding redundant parameters.
External data + Fine‑tuning. This path shows how teams sprinkle in domain‑specific spices after the base reduction. Fresh external data fine‑tunes the SLM for a chosen dish—think pharmaceuticals, legal docs, or IoT telemetry.
3. User prompt ↔ SLM response. The smartphone illustrates on‑device inference. Because the model is compact, it runs locally, answering fast, guarding privacy, and working offline on laptops, phones, or factory boards.
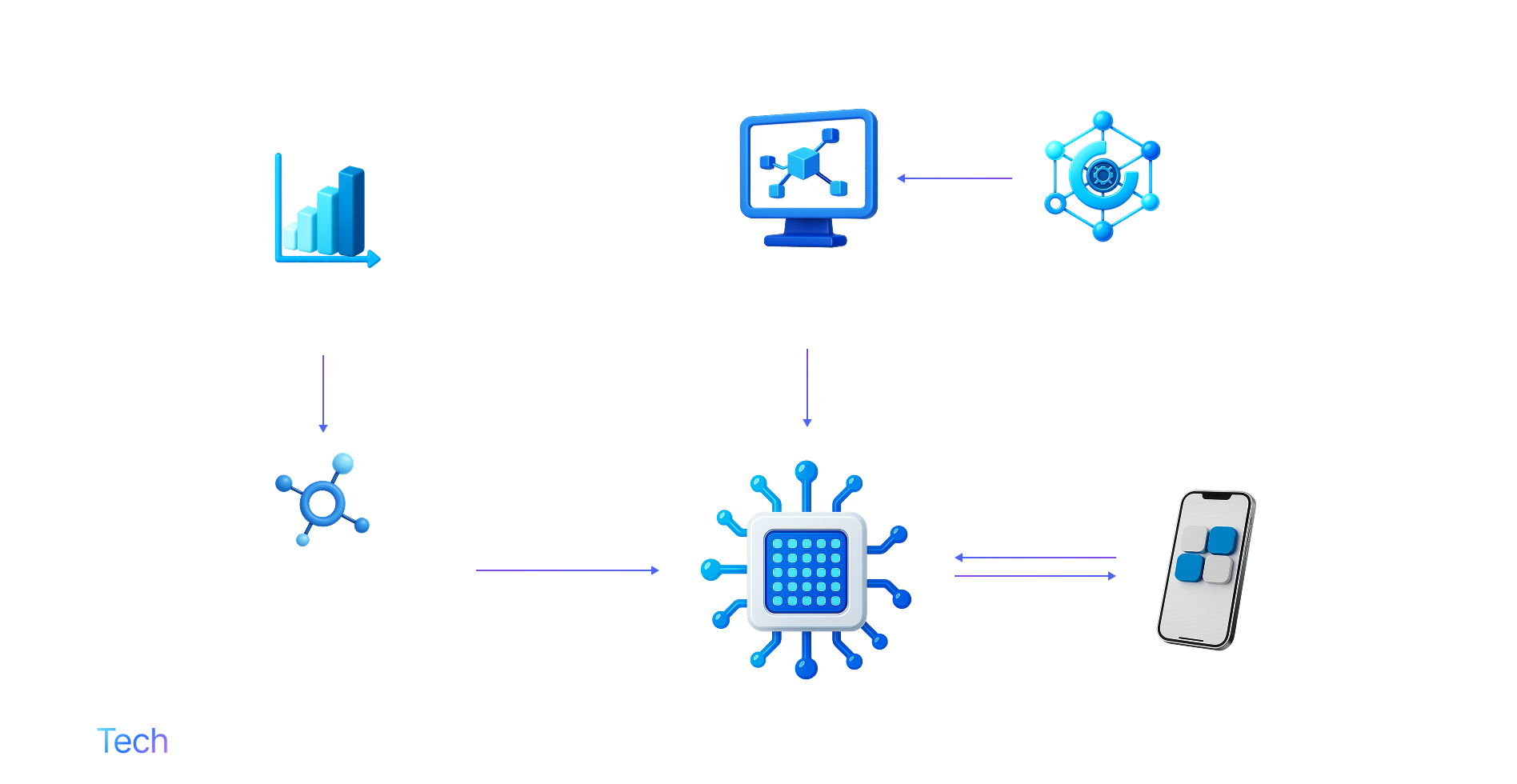
Model compression techniques
SLMs achieve their reduced size through clever optimization of larger models. Key techniques include knowledge distillation, pruning, and quantization – essentially compressing or trimming a large model’s knowledge into a smaller form.
By distilling knowledge from bigger models and removing redundant parameters, SLMs can capture the core capabilities of LLMs while using far less processing power. This makes them ideal for scenarios like edge computing and mobile applications where efficiency is critical.
In practice, an SLM often starts from an existing LLM’s architecture and is then fine-tuned or architecturally optimized to create a leaner model that still performs well on targeted tasks.
As a result, heavy LLM knowledge enters on the left, is condensed in the middle, enriched on the top, and finally served at the edge, delivering accurate answers without a cloud kitchen.
5 Key Benefits of Small Language Models
Small language models turn AI into a controllable, sustainable asset rather than a runaway expense. Here is why teams increasingly swap a monolithic LLM for a fine‑tuned SLM:
1. On‑premise freedom
Deploy SLMs inside any data center, your own racks, a European colocation facility, or a sovereign cloud, and stay immune to geo‑blocking or political turbulence. Because the model lives under your roof, latency drops, data never crosses borders, and licensing terms stay firmly under your control.
72% of enterprise executives rank data security as their top concern when rolling out generative AI, up 40% points year‑over‑year.
2. Tighter output control
A finely scoped SLM knows only the domain you train it on. That laser focus slashes hallucinations and rogue tangents, letting reviewers approve responses in minutes, not hours. Content teams gain confidence that every generated snippet stays on brand, on topic, and fact‑checked against your private knowledge base.
Fine‑tuning Llama‑2 with Direct Preference Optimization reduced factual error rates by 58% compared with the base model.
Businesses cite inaccurate answers as a fast‑rising risk, UK SMEs flag the issue in 40 % of cases, up from 14 % last year.
3. Data security by design
Sensitive records, health data, financial statements, or customer logs, never leave the firewall. Queries travel a few meters over your internal switch instead of thousands of kilometers to a public endpoint. This containment simplifies audits, satisfies GDPR’s data‑residency clauses, and keeps CISOs sleeping at night.
According to the IBM Cost of a Data Breach 2024 report, the average global breach cost has reached $4.88 million.
4. Regulatory resilience
Many popular SLMs ship with liberal open‑source licenses, so you compile once and run forever. Even if a vendor goes bust or a regulator forces a cloud LLM offline, your self‑hosted model keeps answering tickets and powering workflows. Business continuity moves from “hope” to “guarantee.”
The penalties for HIPAA violations include civil monetary penalties ranging from $141 to $2,134,831 per violation, depending on the level of culpability. Criminal penalties can also be imposed for intentional HIPAA violations, leading to fines and potential imprisonment.
5. Lower TCO and greener ops
A fraction of the parameters means a fraction of the GPUs. Reduced power draw and cooling cut OPEX, while slimmer hardware footprints delay CAPEX refresh cycles. Finance applauds the savings; sustainability teams celebrate the smaller carbon footprint in the next ESG report.
Fewer parameters translate to decreased processing times, allowing SLMs to respond quickly. For instance, Granite 3.0 1B-A400M and Granite 3.0 3B-A800M have total parameter counts of 1 billion and 3 billion, respectively, while their active parameter counts at inference are 400 million for the 1B model and 800 million for the 3B model. This allows both SLMs to minimize latency while delivering high inference performance.

6. Seamless integration
SLMs arrive as lightweight Docker images or ONNX bundles you drop into existing pipelines. Plug them into Microsoft Fabric dashboards, call them from Azure ML notebooks, or embed them in on‑prem SQL procedures, no exotic adapters, no vendor lock‑in. Your current tech stack stays intact while the model quietly amplifies its intelligence. A production‑ready Phi‑3‑mini INT4 file is only 2.2 GB, small enough to tuck inside a Docker image or drop into ONNX Runtime.
By mixing these advantages, SLMs give enterprises a secure, cost‑effective route into generative AI while preserving full control over data and destiny.
Challenges and Limitations of Small Language Model
Small language models give teams speed, privacy, and a lighter bill, but no tool comes without trade‑offs. Before you roll an SLM into production, map the edges of its comfort zone. Smaller context windows, narrow vocabularies, and stricter data demands can trip up workflows the moment users push beyond a single domain or language. Knowing these limits up front helps you design guardrails, fallback routes, and MLOps routines that keep service levels intact.
Challenge #1. Limited context window and shallow reasoning
When an SLM can hold only a short slice of conversation or document, it struggles to track long chains of logic. Complex agreements, multi‑step troubleshooting, or multi‑file code reviews can slip through the cracks, forcing teams to jump between tools or escalate to humans.
Solution from HW.Tech. Fine‑tune separate language packs on top of a shared base, or weave a language‑detection layer that selects the right SLM, or calls a multilingual LLM, only when needed. Our privacy‑first Healthmind AI chatbot follows this pattern, automatically switching language packs to serve D‑A‑CH markets without losing tone. Read the case to learn how.
Most small models focus on one language or tone, so global teams hit coverage gaps. Legal teams in another region may receive awkward translations, or marketing teams may see inconsistent voice across campaigns.
Challenge #2. Narrow, domain‑bound knowledge
An SLM thrives on the data it knows and fumbles once users wander outside that comfort zone. Off‑topic questions can yield confident yet wrong answers, eroding trust and risking brand damage when misinformation escapes into customer‑facing channels.
Solution from HW.Tech. Curate and refresh the training corpus, add incremental fine‑tunes as the business expands, and deploy real‑time intent filters that flag or redirect stray prompts.
This rolling fine‑tune pipeline powers Healthmind Daily Digest, where we continuously update 20 + policy sources to keep summaries precise. Explore the full case for context.
Challenge #3. Limited multilingual and stylistic reach
When an SLM can hold only a short slice of conversation or document, it struggles to track long chains of logic. Complex agreements, multi‑step troubleshooting, or multi‑file code reviews fall through the cracks, forcing teams to escalate to humans or switch tools.
Solution from HW.Tech. Break input into smaller, well‑ordered chunks, pair the SLM with a retrieval‑augmented database, or route deep‑reasoning questions to a larger model while keeping routine queries local. We applied this hybrid retrieval strategy in DoBo, our automated value‑dossier generator. See the project for details.
Challenge #4. Ongoing MLOps requirements
Even a lean model drifts as products, regulations, or customer slang evolve. Bias can creep in, and performance can degrade unnoticed, leading to compliance headaches or degraded user experience.
Solution from HW.Tech. Establish a lightweight yet continuous MLOps loop: monitor outputs, collect feedback, schedule periodic re‑training, and run automated bias checks before each release.
Challenge #5. Dependence on an upstream LLM for edge cases
Many architectures cascade from an SLM to a larger LLM when confidence drops. While this safety net improves accuracy, it adds latency, cost unpredictability, and integration complexity.
Solution from HW.Tech. Define clear confidence thresholds, cache frequent fallback answers, and negotiate predictable capacity with the LLM provider so the hybrid stack remains smooth, secure, and budget‑friendly.
Treat these constraints as design guideposts, not roadblocks. Pair a lean SLM with robust data pipelines, periodic re‑training, and an optional LLM safety net. You’ll keep latency low, protect sensitive data, and still deliver dependable AI, without getting blindsided when the model meets a problem bigger than its parameter budget.
Small Language Models Examples and Use Cases
Below is a quick tour of today’s most popular small language models (SLMs), from ultra‑lean DistilBERT to enterprise‑ready Granite 3.0. Each row shows parameter count, standout capability, and where you can spin it up, so you can match the right model to your edge device, chatbot, or RAG workflow.
Model family | Parameter sizes | Distinguished traits | Deployment options |
| 66 M (base); Tiny 4.4 M, Mini 11.3 M, Small 29.1 M, Medium 41.7 M | Knowledge‑distilled BERT—40 % smaller, 60 % faster, and still preserves 97 % of BERT’s accuracy | Hugging Face, ONNX, mobile SDKs | |
| 2 B, 7 B, 9 B (Gemma 1 & 2); distilled from Gemini tech | Lightweight open models with Gemini‑grade weights; CodeGemma variant for coding | Google AI Studio, Kaggle, Hugging Face | |
| not disclosed | Cost‑efficient multimodal sibling of GPT‑4o; powers ChatGPT Free/Plus/Team | ChatGPT UI, OpenAI APIs | |
| 2 B, 8 B plus MoE SLMs | Enterprise‑tuned models (cyber‑sec, RAG, tool‑use); low‑latency MoE variant | IBM watsonx, Google Vertex AI, Hugging Face, NVIDIA NIM, Ollama, Replicate | |
| 1 B, 3 B (quantised versions ≈ ½ size, 2‑3× faster) | Multilingual text‑only models, open licence | Meta download, Hugging Face, Kaggle | |
| 3 B, 8 B | 128 k context; 8 B uses sliding‑window attention for rapid inference; beats 7 B predecessor on knowledge & maths | Mistral Endpoints, Hugging Face | |
| Phi | 2.7 B (Phi‑2), 3.8 B (Phi‑3‑mini); 7 B variant announced | Long context for reasoning over full docs; designed as teaching example of “small‑is‑mighty” | Azure AI Studio, Hugging Face, Ollama |
Standout SLM to Consider
As you have seen above, there are a number of different SLMs to choose from. Each one has its distinct advantages and disadvantages. Naturally, choosing the best SLM is all about the context.However, in the race of SLMs, there are several frontrunners. These are the models that offer tremendous processing power and speed, regardless of their size. Introducing Phi-4. Take a closer look at Phi-4’s performance compared to some industry leaders. Notably, the model outperforms even some leading LLMs.
These examples prove that smaller doesn’t mean weaker. By selecting an SLM whose strengths align with your task, be it mobile inference, regulated data processing, or low‑latency customer support, you gain the agility of modern AI without the heavyweight cost or footprint of an LLM.
LLM vs. SLM: A Detailed Comparison

Side‑by‑side, the table below shows where a small language model (SLM) excels and where a large language model (LLM) still dominates. Scan each row to gauge the trade‑offs, power, cost, privacy, and deployment footprint, before you commit compute or budget.
Category | Small Language Models (SLMs) | Large Language Models (LLMs) |
Definition | Compact AI models trained on smaller datasets to solve focused tasks efficiently. | Expansive AI models trained on massive datasets to perform a wide range of complex tasks. |
Size | Fewer parameters (millions to low billions). | Vast number of parameters (tens to hundreds of billions). |
Training Data | Specialized or curated datasets; domain-specific knowledge. | Broad and generalized datasets covering diverse domains and languages. |
Performance | High accuracy for specific, narrow tasks; struggles with broad generalization. | Strong generalization across multiple tasks and topics but may hallucinate more often. |
Hardware Requirements | Runs on modest hardware (even edge devices); lower computational and storage demands. | Requires powerful GPUs, TPUs, and significant memory/storage resources for training/inference. |
| Latency/Speed | Faster response times and lower latency, ideal for real-time applications. | Slower due to larger model size and complex computations. |
Cost | More affordable to train, deploy, and maintain. | High development, training, and maintenance costs. |
| Fine-tuning | Easier and quicker to fine-tune for specific applications. | Fine-tuning is complex, resource-heavy, and time-consuming. |
| Energy Efficiency | Consumes significantly less energy, supporting eco-friendly AI initiatives. | High energy consumption due to large model complexity. |
Deployment Flexibility | Can be deployed on local devices, IoT hardware, or small-scale cloud environments. | Typically deployed on high-end cloud infrastructures; limited edge deployment capability. |
Use Cases | Chatbots, virtual assistants, customer support, embedded AI in devices, industry-specific apps. | Content generation, complex research analysis, multilingual translation, coding assistants. |
| Security/Privacy | Enhanced privacy—data can stay local, minimizing exposure risks. | Centralized processing often raises concerns over data privacy and security. |
Customization | Highly customizable to niche tasks and company-specific needs. | Customization possible but costly and complicated. |
| Examples | Proprietary SLMs for customer service, SLMs in smart home devices. | OpenAI's GPT-4, Google's Gemini, Meta's LLaMA models. |
| Challenges | Limited scalability; performance can plateau on broader problems. | Expensive scaling; more prone to hallucinations and biases without frequent tuning. |
| Future Outlook | Expected to grow rapidly in adoption for edge AI, mobile, healthcare, and enterprise solutions. | Will remain essential for advanced research, multi-functional platforms, and knowledge work. |
No single model wins every scenario. Choose an SLM when you need speed, edge deployment, and tight control. Basically, reach for an LLM when broad reasoning or multilingual creativity matters. Blend the two for a future‑proof, cost‑balanced AI stack.
How to Choose Between SLM vs. LLM?

Picking the right model is a business decision, not just a tech choice. Use the checklist below to balance speed, cost, privacy, and innovation before you lock in your architecture.
Step 1. Explore the task scope
Identify whether the workload is broad or niche. Highly specialized workflows—think invoice parsing or device‑side sentiment analysis. Benefit from an SLM tuned for laser‑focused accuracy.
Step 2. Audit data governance
Map where the data lives and which regulations apply. If policy forbids external APIs or cross‑border transfers, an on‑device SLM keeps every byte inside your perimeter.
Step 3. Measure computational power
Confirm your infrastructure can host a 70‑billion‑parameter giant. If GPUs are scarce or budgets are tight, lean into the efficient footprint of an SLM.
Step 4. Estimate user load
Predict traffic patterns. Massive bursts across thousands of sessions suit horizontally scaled SLM clusters, while a few deep‑thinking queries may justify an LLM.
Step 5. Consider the future roadmap
Plan for growth. If multilingual storytelling or complex research looms, design a hybrid setup. Start with an SLM and escalate to an LLM only when necessary.
Step 6. Run a proof of concept
Benchmark latency, accuracy, and cost with real data. Compare user satisfaction for LLM vs SLM side by side to reveal hidden trade‑offs.
Step 7. Secure executive backing
Translate metrics into ROI:
- lower cloud fees;
- greener ops;
- faster response times.
Executive sponsorship ensures resources and removes last‑minute roadblocks.
No single model wins every scenario. Follow these steps, and you’ll deploy the smallest engine that still delivers the horsepower your users expect, while keeping budgets, compliance, and sustainability targets on track.
HW.Tech's Experience with SLMs
We don’t just talk about SLMs. We build them. Below are three live projects where our team tapped into SLMs to solve real-world business problems quickly and securely.
- DoBo for faster dossiers. Here, we use lean SLM to do the trick. Think pocket scanner plus reference librarian. The idea was to skim 400-page clinical reports to draft value dossiers in just one week. This split slashed writing time by 60 % and cut costs without sending confidential data to the cloud. Clients now push a button and watch weeks of manual work finish before lunch.
- Healthmind Daily Digest for instant market insights. An SLM acts like a newsroom intern, sweeping 20+ policy feeds each morning and boiling them down to bite-sized bullets. When policy wording gets tricky, an AI steps in as the senior editor, clarifying the legal fine print. Users receive a plain-language email digest that lands before their first coffee, keeping teams ahead of regulatory shifts.
- Healthmind AI for private, multilingual chat. We embedded an on-device SLM, a secure pocket AI assistant, so doctors can interrogate study PDFs without exposing data. Role-based access, local parsing, and zero data retention keep HIPAA and GDPR officers happy. The result feels like ChatGPT in a vault: friendly, fast, and fully compliant.
These projects show how mixing SLMs for speed and privacy with LLMs for heavy lifting gives you the best of both worlds. No oversized bills, no data leaks, and no waiting around.
Wrapping Up
Small language models (SLMs) bring AI power to every device, from kiosks to factory sensors. When you weigh performance, privacy, and cost, remember this rule: use the model size that matches the job. By understanding SLM vs LLM, you unlock a balanced AI portfolio that scales from the cloud to the shop floor and keeps your team ready for tomorrow’s language‑driven platform innovations.
Contact HW.Tech and get to know the insider’s look at SLMs and LLMs. Our experts have hands-on experience in building these models. We can both share some interesting insights or build one for your needs.
FAQs
What is SLM?
A small language model is a compact neural network trained on a focused dataset so it can understand and generate text while using a fraction of the parameters and compute, of an LLM.
When should I choose an SLM instead of an LLM?
Pick an SLM when your task is narrowly defined, latency-sensitive, or must run on-premise; reserve an LLM for broad, creative, or highly multilingual workloads.
Can SLMs run on edge or mobile devices?
Yes. Because a small language model has fewer parameters, it fits into smartphones, IoT boards, and even browser-based apps without needing GPU clusters.
How do small language models improve data privacy?
Since SLMs can be deployed locally, sensitive prompts and outputs stay inside your firewall, reducing exposure to third-party clouds and simplifying compliance with GDPR or HIPAA.






